Lec-1 Introduction - Machine learning (台大李宏毅)
本文为台大李宏毅的机器学习入门课程笔记。
第一章:机器学习入门
重点:
- 机器学习分类
- 各个类别总结
机器学习,不同于以往的hand-crafted rule learning, 不是由人给定规则,而是由机器去真实地通过输入的数据,去总结出一些规律。这些规律可能人类已知,也可能未知;可能理解,也可能不理解。但是没关系,人类还是机器的主宰。
下面先来看这张图:

可以看到,机器学习总共可以分为三个步骤:
- 有一系列的model / function (红色)
- 有训练数据(黄色)
- 能够评估function好坏的标准(蓝色)
以监督学习为例,则:
学习过程:
- 从function set 中拿出一个,来作为你认为比较适合这个任务的学习模型$f_1,f_2,…$(带参, 如$y = b + wx$)
- 定义如何衡量学习模型的好坏,即设定一个打分标准(如 mean square erro)
- 把训练数据喂给不同参数的学习模型,从中选出一个最好的,作为学习出来的最终模型$f^*$(参数已确定,如$y = 5 + 3x$)
预测过程
- 用$f^*$来预测测试数据集的结果
- 把得到的结果与测试集的真实结果相比较,计算出准确率
机器学习分类
(ref)
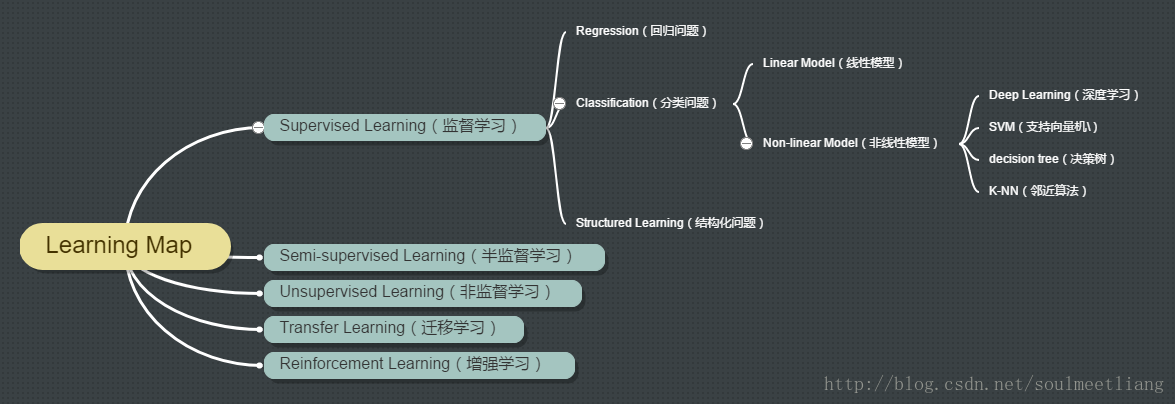
可以看到,在machine learning这个分类下,可以分为5类学习。下面我们一一介绍一下这五类学习方法。
1. Supervised Learning 监督学习
所谓监督学习,就是我们告诉机器说,当看到input1,就输出ouput2;看到input2,就输出ouput2
1.1 Regression 回归问题
The output of the target founction f is ‘scalar’.
如果我们在机器学习中要找的function输出是数值,这样的问题就是回归问题
举个例子: 预测PM2.5进行天气预报。
核心思想:连续函数下的预测

1.2 Classification 分类问题
分类问题,顾名思义,就是对输入的数据进行分类。按照输出结果的个数和中间过程,可以将分类问题各自分为两类
按照输出结果分类
- Binary-Classification 二分类(输出两种结果)
- Multi-class Classification 多分类(输出多个结果)
举例:
- Binary Classification: Spam filtering(垃圾邮件过滤):判断是垃圾邮件,不是垃圾邮件。
- Multi-classification: Document Classification(文件分类):将文件分为政治、经济、体育等多个大类。

按照中间过程分类
- linear model 线性模型:能做的事有限,一些简单的模型可以用它来做,但遇到复杂问题就力不从心了
- non-linear model 非线形模型: 不仅仅是线形分类,可以是经过复杂组合、有层级的分类过程,如现在的深度学习就是一个Non-linear Model,能完成一些很复杂的工作,比如图像分类、下围棋等

1.3 Structured Learning 结构化学习
beyond classification
希望输出是有结构性的数据,比如输入声音讯号,输出文字,而文字有结构;或者做机器翻译,输出的文字也有先后顺序,有结构。

2. Semi-supervised learning 半监督学习
如果数据集中,只有少部分Labelled data(已经标记好的数据),和较大一部分Unlabeled data(未做过标记的数据),那么就称这样的学习过程为Semi-supervised learning。
它利用Unlabeled data来优化function。常用于数据不足时进行学习

3 Transfer learning 迁移学习
如果数据集中,有目标所需的labeled的data,但是有更大一部分的与目标数据无关的labeled 或unlabled data,这种学习就叫迁移学习
4 Unsupervised learning 无监督学习
我们希望机器能够无师自通。在这个数据集中,只有输入input data,没有输出(label),希望机器能够自己学着输出
假设我们今天带机器去动物园让它看一大堆动物,它能不能在看了一大堆动物之后,自己创造一些动物出来😁

5 Reinforcement Learning 增强学习
在监督学习中,是直接告诉输出结果应该是什么;而在增强学习中,我们不直接告诉机器应该输出什么,而是在最后给出一个分数。
比如我们要训练一个增强学习的对话机器人,就把它放到网上,然后让它去跟网友直接对话。最后网友勃然大怒,机器就知道,哦我不能这样做。但它不知道哪里做错了,只知道不能这样。它会自己反省,就像在自学一样。

总结

通常,学习场景(蓝色部分)是我们无法控制。选择哪个学习模型,是由场景来控制的。所以手上有什么样的data,就决定用什么样的模型。如果没有lable,就只能考虑除了监督学习之外的learning。换句话说,如果有label的话,就不要强求用增强学习。而学习目标(红色部分)是我们选择模型的一个依据,是根据问题来决定的。如果是一个分类问题,就用classification来做,就不用regression来做。具体的方法选择(绿色部分)就可以换了,比如同样是non-linear的分类问题,就可以选择不同模型(如SVM,DT,KNN..)来做学习模型。
参考链接:
https://blog.csdn.net/soulmeetliang/article/details/72591054
视频链接: